집합연산자
- 열의 개수와 순서가 모든 쿼리에서 동일해야 한다.
- 데이터 형식이 호환되어야 한다.
- SELECT (열) FROM (테이블) WHERE (조건) [집합연산자] SELECT (열) FROM (테이블) WHERE (조건)
UNION : 연결된 SELECT문의 결과 값을 합집합으로 묶어 준다. 결과 값의 중복은 제거된다.
UNION ALL : 연결된 SELECT문의 결과 값을 합집합으로 묶어 준다. 중복된 결과 값도 제거 없이 모두 출력 된다.
MINUS : 먼저 작성한 SELECT문의 결과 값 중 다음 SELECT 문에 존재하지 않는 데이터만 출력된다. (차집합)
INTERSECT : 먼저 작성한 SELECT문과 다음 SELECT 문의 결과 값이 같은 데이터만 출력된다. (교집합)
위 4개의 집합 연산자들이 어떻게 연산되는지 알아보기 위해 먼저 emp테이블을 복사하여 2개의 새로운 테이블을 만들어보자.
create table emp_1 as select * from emp;
create table emp_2 as select * from emp;테이블을 복사하는 방법은 위와 같다.
이 외에도 여러가지 방법이 있지만 테이블을 생성하면서 복사하는 가장 간단한방법은
CREATE TABEL [생성할 테이블] AS SELECT * FROM [복사할 테이블] ;
이 되겠다.
이제 복사한 테이블에 몇 행을 추가하고 삭제해보자.
행을 추가하는 방법은
INSERT INTO [테이블] VALUES ([컬럼 1 값], [컬럼 2 값] .. );
이다
insert into emp_1 values(1234, 'Sean', 'IT', 8000, '21/02/18', 7000, 2000, 40);
insert into emp_1 values(2345, 'Mason', 'TEACHER', 6000, '21/02/15', 6000, 1500, 50);
insert into emp_1 values(3456, 'John', 'DESIGNER', 7000, '21/01/30', 5000, 3000, 60);이를 이용해 emp_1에 행을 몇 개 추가했다.
행을 삭제하는 방법은
DELECT FROM [테이블] WHERE [조건];
이다. 조건에 맞는 행을 모두 삭제해준다.
delete from emp_2 where job = 'MANAGER';
delete from emp_2 where job = 'PRESIDENT';
delete from emp_1 where job = 'SALESMAN';
delete from emp_1 where job = 'PRESIDENT';이를 이용하여 emp_2와 emp_1의 행 몇가지를 삭제해보았다.
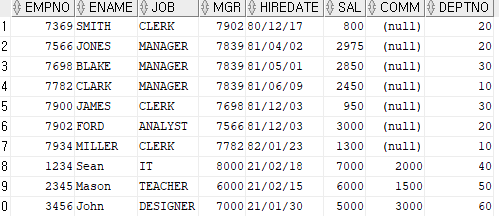

결과는 위와 같다.
이제 두 테이블을 집합 연산자를 사용하여 합치거나 교집합, 차집합을 찾아보자.
UNION (합집합)
select * from emp_1 union select * from emp_2;
결과 중 중복을 제외한 모든 행이 출력된다.
UNION ALL (중복 포함)
select * from emp_1 union all select * from emp_2;
합집합이지만 직업이 CLERK와 ANALYST인 사람들은 중복되어 나오는 것을 알 수 있다.
MINUS (차집합)
select * from emp_1 minus select * from emp_2;
emp_1에 새로 추가했던 IT, TEACHER, DESIGNER 와 emp_2에서 삭제했던 MANAGER 직업을 가진 사람들만 출력되었다.
즉 emp_1에만 있는 내용들이 출력되는 것을 알 수 있다.
INTERSECT (교집합)
select * from emp_1 intersect select * from emp_2;
이번에는 두 테이블에 모두 존재하는 CLERK, ANALYST 직업을 가진 사람들만 출력되었다.
두 테이블 모두 존재하는 값 (중복되는 값) 만 출력되는 것을 알 수 있다.